Database |
The VAS database is an observation-centric implementation of the ISO 19156 / OGC Observations & Measurements (O&M) model. It captures observations (measurements and assertions), keeps procedures, features-of-interest, and results separate and linked, and standardises semantics via controlled vocabularies and units. Platform stack: Custom CeRDI build using PostgreSQL (with time-series support) and services via PostgREST. |
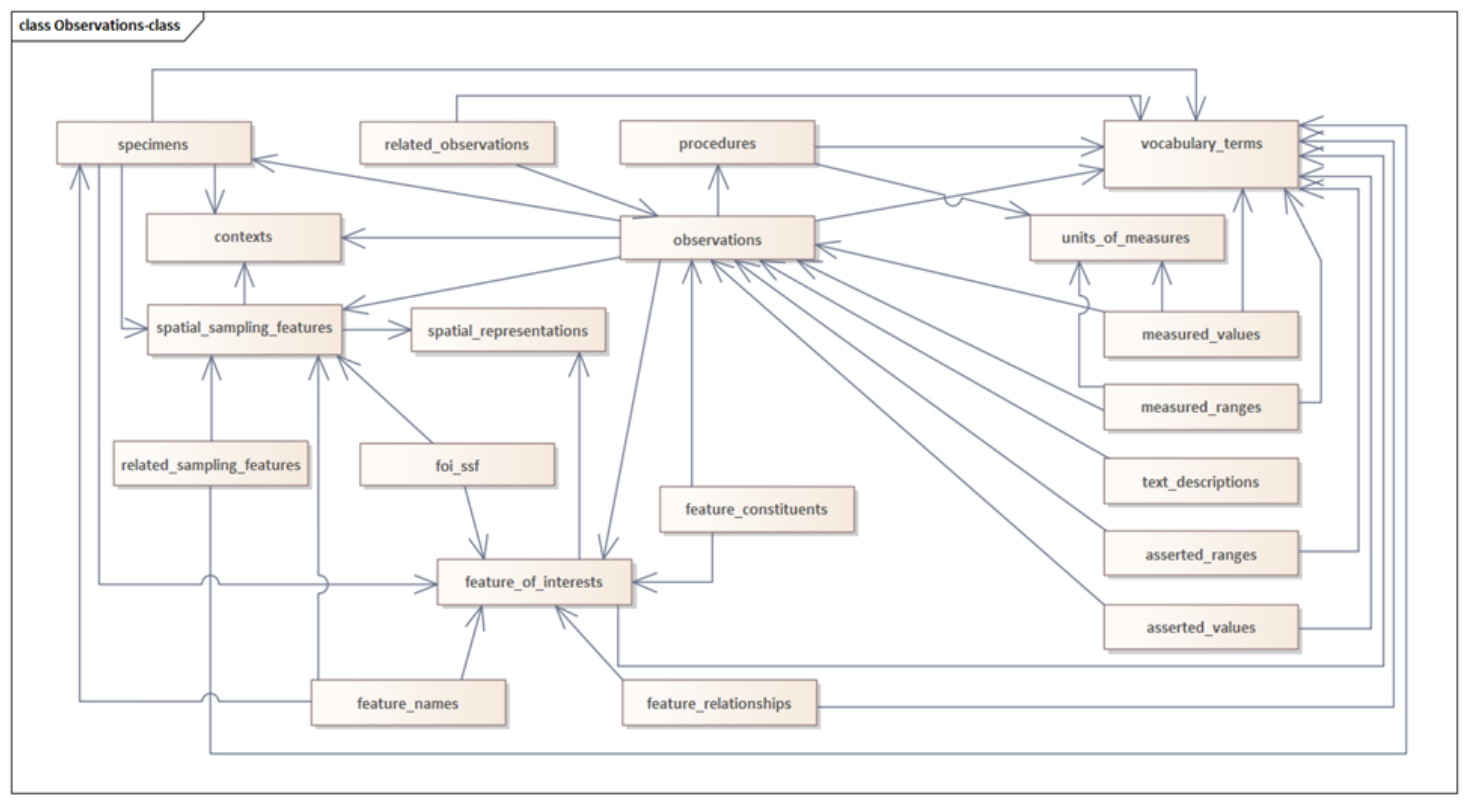
Core Entities (tables) & Relationships The schema mirrors O&M and groups entities into three layers: Observation layer observations – one record per observation (lab or field); links to result tables and to the procedure used and feature(s) observed. Results can be a single value, a range, a term, a term-range, or a text description. measured_values / measured_ranges – numeric results with units; range tables store min/max plus qualifiers. asserted_values / asserted_ranges – categorical results as controlled terms (and ranges of terms). text_descriptions – narrative result when the outcome is descriptive (no number/term). related_observations – links between observations (e.g., “previous application rate”, “alternative result”).
Feature & sampling layer features_of_interests – the real-world soil feature (e.g., soil layer, horizon). spatial_sampling_feature – the sampling construct used to sample the real feature (e.g., site, core, plot). specimens – physical samples linked to sampling features; observations can reference a specimen and the ultimate feature-of-interest.
Semantics & governance layer procedures – how the property was observed/measured; binds to observed property and unit expectations. vocabulary_terms – the controlled lists behind properties, methods, qualifiers, roles, etc., with external persistent identifiers. units_of_measures – units with labels, notation, and quantity kind, linking to authoritative ontologies (e.g., QUDT).
|  
|
By strictly separating observation/procedure/feature/result and using controlled vocabularies, the database scales to new domains, new methods, and multi-lab datasets without reshaping the core schema. |
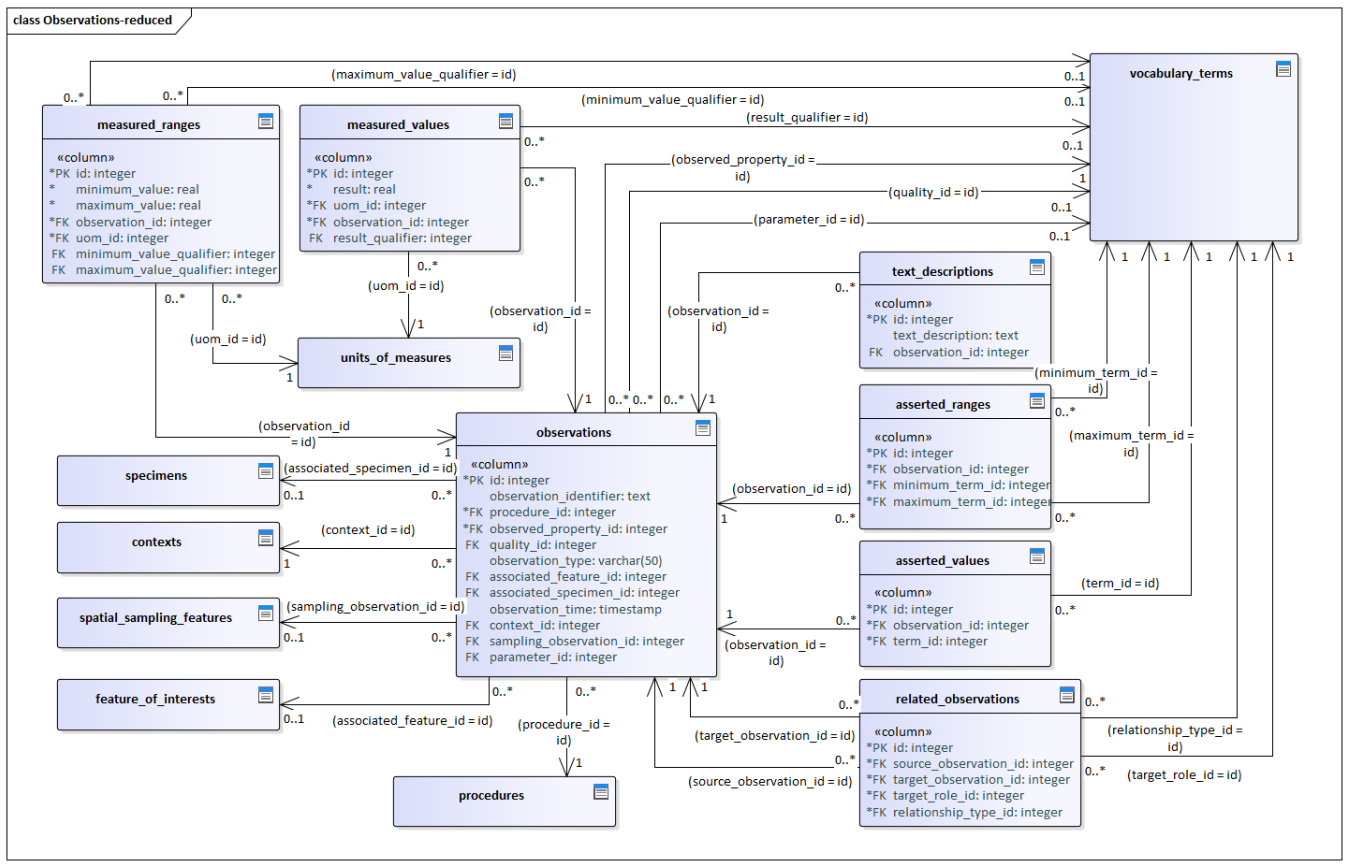
Result Types & Storage Pattern Each observation has one of five result types; each type is stored in its own table and linked to the observation (and to UoM where relevant): Numeric value → measured_values (with uom_id, optional qualifier)
Numeric range → measured_ranges (min/max with qualifiers & uom_id)
Term value → asserted_values (term from vocabulary_terms)
Term range → asserted_ranges (lower/upper terms)
Text description → text_descriptions
|
System Flow Ingest → Map → Store → Publish Ingest/Staging: Incoming datasets (via the uploader) are mapped to the observation model entities: Observation, Procedure, Observed Property, Feature-of-Interest (and Sampling Feature/Specimen for spatial lineage). Semantic binding: Values are validated/mapped to vocabulary_terms (properties, methods, roles) and units to units_of_measures to maintain consistent semantics. Storage Create observations records Persist results into the correct result table (numeric / range / term / term-range / text) Link to UoM, qualifiers, and related observations where applicable.
Publication: Expose validated data via PostgREST endpoints that serve JSON-LD, aligned with SOSA/Schema.org, for discovery and reuse.
To know more information regarding Database: Database Documentation |